[[TOC]]
Architecture Deep Dive
Event Driven Architecture is an upgrade to a monolithic architecture.
- Monoliths fail together scale together, and bill together.
Tiered architecture splits up the monolith into different platforms for each of the stages of the application. These are still coupled together, but could be a bit more elastic. Each of these tiers can then be scaled independently. If we place load balancers between these tiers, we can create more elasticity. Tiered architectures create a dependence on the other tiers.
Queues
Queues decouple architecture.
- When the upload is complete, it stores the video in S3 and adds a message to the queue. It doesn't pass anything to the processing tier, nor does it even know it's running. It simply adds a message that says "there's something in S3 that needs processing."
- Other people may be uploading videos as well and those all do the same thing, go into S3 and a message gets added to the queue
- An autoscaling group sits alone and is triggered by the queue length. If there are two videos in the queue, it spools up 2 EC2 instances and then processes the message from the queue which tells the instance where the video is, and what processing needs done to it.
- The instance then processes this video. Once the videos are completed, the message is deleted from that queue and then the autoscaling group scales ini accordingly to how many messages are in the queue, which is zero at this point.
Microservices
These further decouple architectures by having services that fall under 3 categories
- Producers
- Consumers
- or Both
Event Driven Architecture
Event Producers - created when something happens. When something is uploaded or submitted. Event Consumers - these are created when there is something to consume or process Event Routers - these move things from producers to consumers Event Bus - a constant stream of data.
Nothing is sitting there running and waiting Once the actions are taken, it goes back into waiting state. These only consume resources while handing events - serverless :)
AWS Lambda in Depth
Lambda is a FaaS product - Function as a Service - short running and focused. Lambda function is a piece of code that lambda runs These functions use a runtime (Python 3.8) Lambda loads functions and runs them in that runtime environment. You are only billed for the duration that a function runs. Lambda is a key part of serverless architecture.
Deployment package is downloaded and executed in the runtime environment Different languages (Python, Ruby, Go, Java) NOT DOCKER. That is Container computing.
Assume that every time a Lambda function is invoked, that it is running in a new runtime environment. Tips:
- Max time: Lambda has a 15minute timeout.
- Lambda is given public networking by default so that it can access public AWS services and the public Internet.
- No customer specific VPC networking is required
- Lambda functions have no access to VPC based services unless Public IPs are provided and security controls allow external access.
- Lambda functions that run in a VPC obey all the VPC networking rules.
- Cannot access outside the VPC without networking or VPC endpoints to the public services.
- NATGW and IGW are required for VPC Lambdas to access Internet resources.
- Treat lambda functions running inside VPCs as anything else that runs inside the VPC.
Security
Lambda has resource policies that control what services and accounts can invoke the lambda functions. Lambda execution roles are IAM roles attached to lambda functions which control the permissions that the lambda function receives.
Logging
CloudWatch, Cloudwatch logs, and X-Ray Logs from execution - Cloudwatch logs. Metrics - stored in Cloudwatch Lambda can be integrated with X-Ray for distributed tracing. Cloudwatch logs requires permissions via the execution role.
Invocation
- Synchronous - CLI or API invoke lambda function and waits for a response. Response responds or fails. Response fails during that request.
- Asynchronous - typically used when AWS services invoke lambda functions. Function code needs to be idempotent.
- Event source mapping - Typically used on streams or queues which don't support event generation to invoke Lambda (Kinesis, DynamoDB streams, SQS) Event source mapping pulls a source branch and then sends that to Lambda as an event batch. All must succeed or the entire event batch fails. Permissions from the lambda execution role are used by the event source mapping to interact with the event source.
Versions
Immutable $latest - latest version of the function Aliases.
Lambda start up times
An execution context is the environment that a Lambda function runs in.
- A cold start is the full creation and configuration of a lambda function, including the code download.
- a warm start is the reuse of an execution context. If too much time passes, the execution context is reset. A Lambda function can reuse an execution context but has to assume that it can't. You can't write in something that expects code to already exist in a context.
- You can pre-provision these execution contexts to save time as well.
CloudWatch Events and EventBridge
If something happens or we want something done at a specific time, do something.
- Use EventsBridge over CloudWatch Events. It's basically V2 of CloudWatch Events.
- there is a default event bus for the account
- Cloudwatch has one bus (implicit)
- EventBridge can have multiple event busses.
- Rules match incoming events or match the schedule (CRON jobs)
- routes 1 or more targets such as Lambda.
Default Event Bus
- EC2 state stops, then an event is generated and placed into the Event Bus.
- If there is a rule that matches EC2 state stoppage, it will pull the JSON payload from the Event Bus and pass it on to the target - Lambda to do something as a response to that event.
Demo - Automated EC2 Start/Stop and protect using Lambda
Demo
Serverless Architecture
Serverless is not just one single thing.
- Applications are a collection of very small and specialized functions
- These run in stateless and ephemeral environments
- Everything is Event Driven - runs only when something is being used
- FaaS is used wherever possible for compute functionality.
- Managed services are used wherever possible.
Example
SNS - Simple Notification Service
Public AWS Service - network connected with Public Endpoint Coordinates the sending and delivery of messages Messages are greater than or equal to 256kb payloads.
- Publisher sends messages to a TOPIC
- Subscribers receive messages from a TOPIC.
- These can be HTTP(s) Email, SQS, Mobile Push, SMS message, or Lambda.
- You can also publish to a subscribing API that also publishes to a TOPIC
- FANOUT is when you publish a single message to many SQS queues
Delivery status tracks the success of the delivery Delivery retries ensure reliable delivery HA and Scalable Capable of SSE Cross account via TOPIC Policy
Step functions
15 minute max execution time
- can chain lambda functions together
State Machines�
States are things which occur Start > States > End Maximum duration is 1 year Standard Workflow and Express Workflow Started via API gateway, IOT rules, EventBridge or Lambda Amazon States Language (ASL) - JSON template IAM Role is used for permissions
States
- Succeed and Fail
- Wait
- Choice
- Parallel
- Map
- Task (Lambda, Batch, DynamoDB, ECS, SNS, SQS, Glue, Sagemaker, EMR, Step Functions)
API Gateway
Used to create and manage APIs Endpoint or entrypoint for applications Sits between applications and integrations (services) HA, scalable, handles authorisation, throttling, caching, CORS, transformations, OpenAPI spec, direct integration and much more. HTTP, REST APIs
Phases
Request Integrations Response
Authentication
Endpoint Types
Edge-Optimized Regional Private - only accessible within a VPC via interface
Stages
APIs are deployed to stages, prod, dev, etc. Can create canary deployments or promote them or remove the canary back to the original stage
Errors
400 series - client errors 500 series - valid, backend error
400 - bad request 403 - access denied 429 - exceeded throttling
502 - Bad Gateway Exception - bad output. 503 - Service Unavailable 504 - integration failure - 29s
Caching
- 300 seconds
- can be encrypted
- 500mb to 237GB
- calls to the backend only on a cache miss
Lambda Professional
AWS Lambda
Lambda is a Function as a Service (Faas) which takes a bit of code and runs it using a runtime and then charges you for running it.
- Serverless architecture
- uses a runtime environment that you can set the memory allocation for.
- runtime is mostly stateless, which makes it ephemeral.
- memory is allocated directly, and the CPU is allocated indirectly
- runs for 15 minutes before it times out. Anything longer than 15 minutes cannot be used by Lambda.
Deployment package is downloaded into that runtime and then executed. Runtime can be Python, Ruby, Java, Go, C# but not Docker. Docker is not Lambda.
Use Cases
Serverless applications (S3, API Gateway, Lambda) File Processing (S3, S3 Events, Lambda) Database Triggers (DynamoDB, Streams, Lambda) Serverless CRON (EventBridge/CWEvents and Lambda) Realtime Stream Data Processing (Kinesis and Lambda)
Public Lambda
Public Lambda can access the public AWS Services such as SQS or DynamoDB and the public Internet.
These public Lambda functions have no access to VPC based services unless public IP's and security controls allow external access.
Private Lambda
This is Lambda that runs within a VPC. These Lambda functions obey all of the VPC networking rules. 90 second setup to create the ENI required for Lambda to access your VPC.
Security
Lambda runs in the runtime environment and needs an execution role attached in order for the function to run.
- Lambda execution roles are IAM roles attached to functions which control the permissions the Lambda function receives.
- Lambda resource policy controls what services and accounts can invoke these Lambda functions.
Logging
Lambda uses Cloudwatch, Cloudwatch Logs, X-Ray
- Logs from Lambda executions goes into Cloudwatch logs
- Metrics (invocation success/failure, retries, latency) are stored in Cloudwatch.
- Lambda can also be integrated with X-Ray for distributed tracing.
- Cloudwatch Logs requires permissions via an Execution Role.
How to Invoke
- Synchronous Invocation - CLI or Client sends data to the function. The function then returns a result. Client reprocesses it.
- Asynchronous Invocation - When an AWS service sends data to the function. Lambda will reprocess any retries. These retries must be idempotent. Events can be sent to destinations (SQS, Lambda, SNS, EventBridge.) Events can also be sent to a dead letter queue if they fail to process.
- Event Source Mapping - Producers send to the Kinesis Data Stream. Event Source Mapping pulls from the Source Batch of the Kinesis Data Stream and then sends an Event Batch to Lambda. All of the batch must be processed for the Event Batch to be successful. Either the entire batch works or it doesn't work. Remember your 15 minute limit with these batches. Permissions from the Lambda execution role are used by the event source mapping to interact with the event source.
Versioning
Lambda functions have versions - v1, v2, etc.
- A version is the code plus the configuration of the Lambda function.
- versions are immutable, which means that once published, it never changes
- $latest points to the latest version so that you don't need to specify and update the newest versions. $latest is not immutable.
- you can also use aliases (dev, stage, prod) to name specific versions of Lambda functions.
Execution Context
An execution context is the environment that a Lambda function runs in.
- A cold start is the full creation and configuration of a lambda function, including the code download.
- a warm start is the reuse of an execution context. If too much time passes, the execution context is reset. A Lambda function can reuse an execution context but has to assume that it can't. You can't write in something that expects code to already exist in a context.
- You can pre-provision these execution contexts to save time as well.
Lambda Function Handler
- Lambda functions have lifecycles. This includes the Execution Environment.
- INIT - creates or unfreezes the execution environment.
- INVOKE - runs the function handler (Cold Start)
- Next INVOKES - run the warm start using the same environments.
- SHUTDOWN - terminates the execution environment which will result in a Cold start when it needs another environment.
Well constructed Lambda functions should assume a cold start but also be able to take advantage of a warm start (if connection does not exist, connect, else continue)
Quick Demo
- Navigate to the Lambda console in your AWS management account.
- Create Function
- Name function and set the runtime.
- You can scroll down and run the test with the sample code.
- Paste in the terrible sample code below.
import json, os, time
def lambda_handler(event, context):
db=False
if db==False:
print ("Connecting to the BabyYoda Database")
time.sleep(3) # fake it til you make it
print ("Connected to BabyYoda Database.")
db=True
if db==True:
print ("Already connected to database.")
print ("Executing the BabyYoda Application.")
print ("End of BabyYoda Application.")
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Finished!')
}
- Run this code as well.
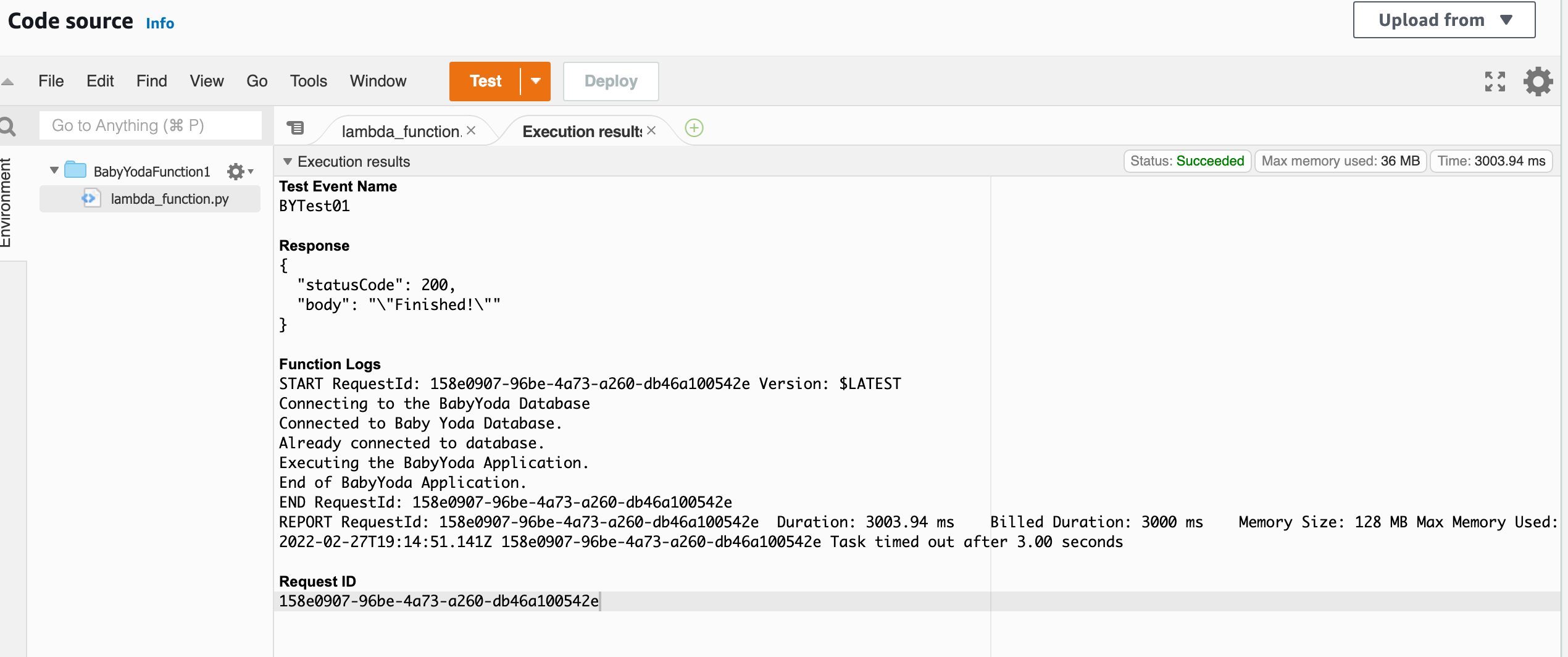
- Notice that you get a timeout error. On the configuration tab, you can set the timeout for about a minute so that this code runs.
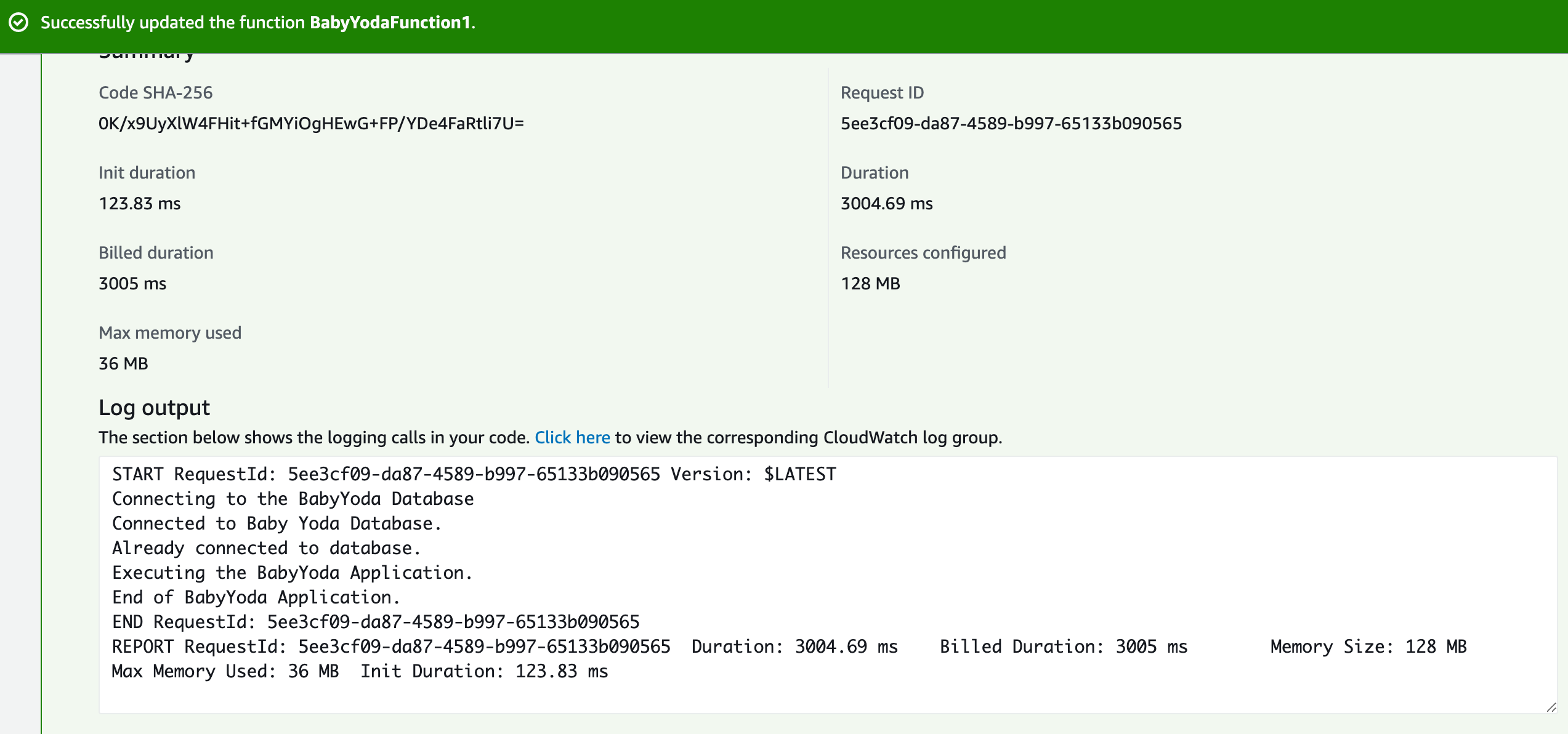
- Notice that it has an init duration of 123.83 ms. That is the time that it takes to set up this execution environment. Run the test again and that should disappear because we're using the same execution environment the second time.
- Copy this updated code sample below.
import json, os, time, logging
print('Creating Execution Environment')
db=False #
if db==False:
print ("Initializing connection to BabyYoda Database new execution environment.")
time.sleep(3) #fake it til you make it
print ("Connected to BabyYoda Database, new execution environment.")
db=True
def lambda_handler(event, context):
global db
if db==False:
print ("Initializing connection to BabyYoda Database. Existing")
time.sleep(3) # fake it til you make it.
print ("Connected to BabyYoda Database. Existing")
db=True
if db==True:
print ("Connection to BabyYoda Database exists, running app")
print ("Running BabyYoda Application")
return { 'statusCode': 200, 'body': json.dumps('Finished!') }
- Initial run connects to the database. You'll see an init duration of 3200+ ms.
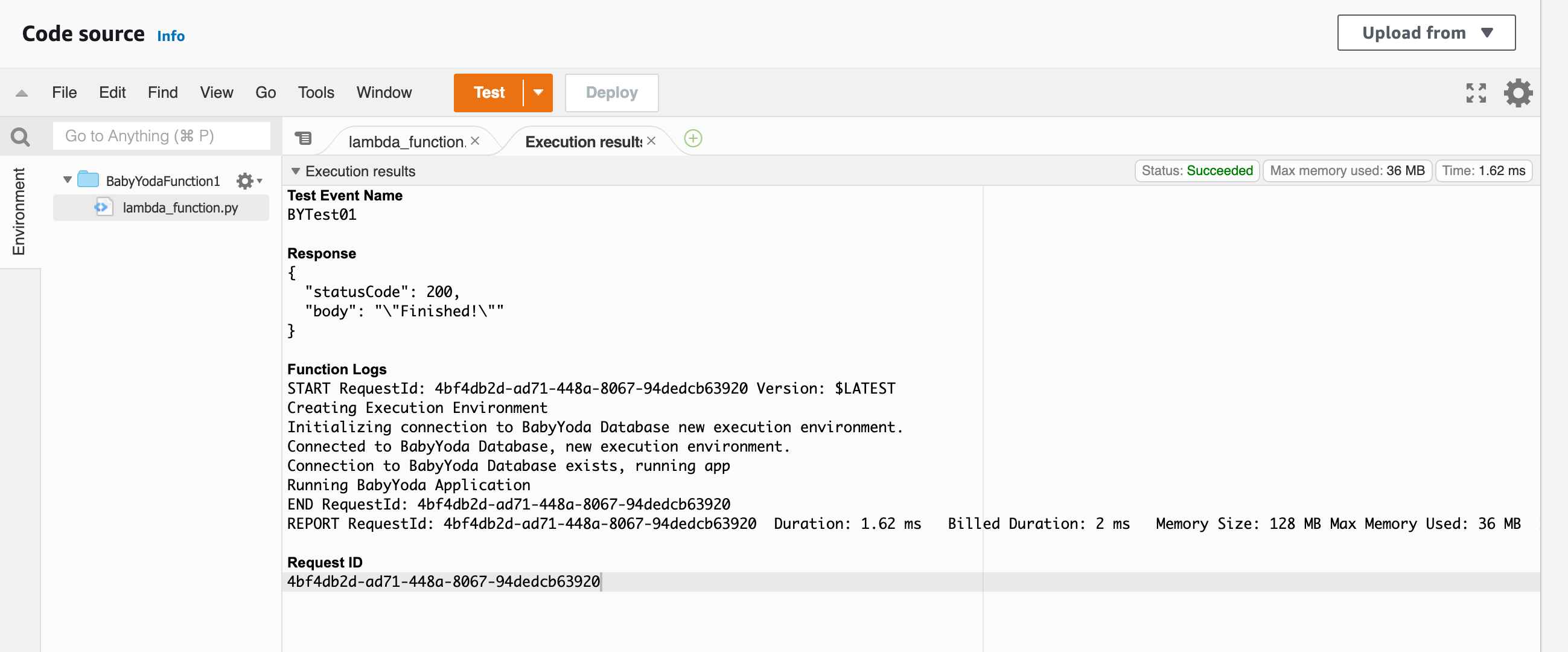
- Subsequent runs are already connected to that database and don't show the init duration and the run time as shorter. This is why you need to build your Lambda code to assume that it runs on a new execution environment, but can run on an existing one for efficiency.
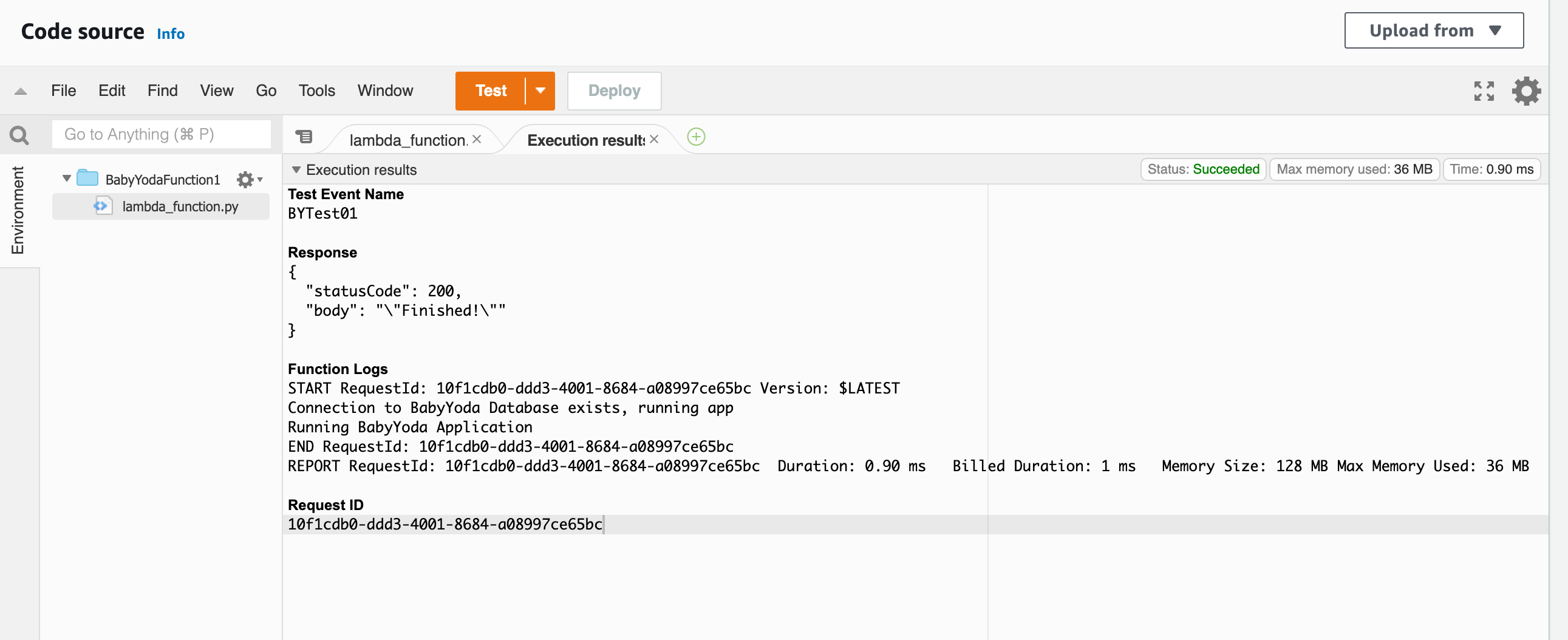
- Note the name of the initial function
lambda_handler. Scroll down to the Runtime settings and notice that the name of the function is set up to call this function within the code.
- This is where it ignores the first part of the code and simply calls the function within the code. This differentiates between a warm start and a cold start. Make sense?
- Cleanup is to delete the function.
Lambda Versions
The previous demo, you pretty much just created on function ($latest) and then overwrote on top of that function without versioning. When you publish a function, you create an immutable version of that function, meaning that any edits to that function will be a new version of that function. This allows you to forever specify v1 of a function even though you might go through multiple iterations of that function and someday end up with a v12 or something.
- this includes the function code, the dependencies, the runtime, settings and environment variables.
- includes a specifically unique ARN for that function version.
Qualified vs Unqualified function ARNs
- Qualified ARN points to a specific version
- Unqualified ARN points at the $latest version of the function, not specific
Lambda Aliases
An alias is a pointer to a specific function version Prod can point to version1 UAT can point to version2 Dev can point to version3
You can update the aliases to change the versions that they represent. Lets say we want to move v3 from Dev to production, we can then change UAT to v3, assuming that passes, then we can set Prod to v3.
We can also route these aliases, meaning that a certain percentage can be on v1 and a certain percentage can be at v3. This creates a rolling type of upgrade where we can test our updated code in the production environment (eek!)
- need same dead letter queue and same role. Cannot be set to $latest for obvious reasons.
Quick Lambda Alias Demo
- Navigate to the Lambda console in the Management account
- Click on Create Function and then click on
Author from Scratch. - Name this as you wish and select Python as the runtime.
- Paste this code below. We shall call this v1:
import json
def lambda_handler(event, context):
print ('BabyYoda says hi.')
print ('This is v1 of the code')
print ('Gimme Gimme Chicky Nuggies')
return "This is the way."'
- Deploy this and then Test.
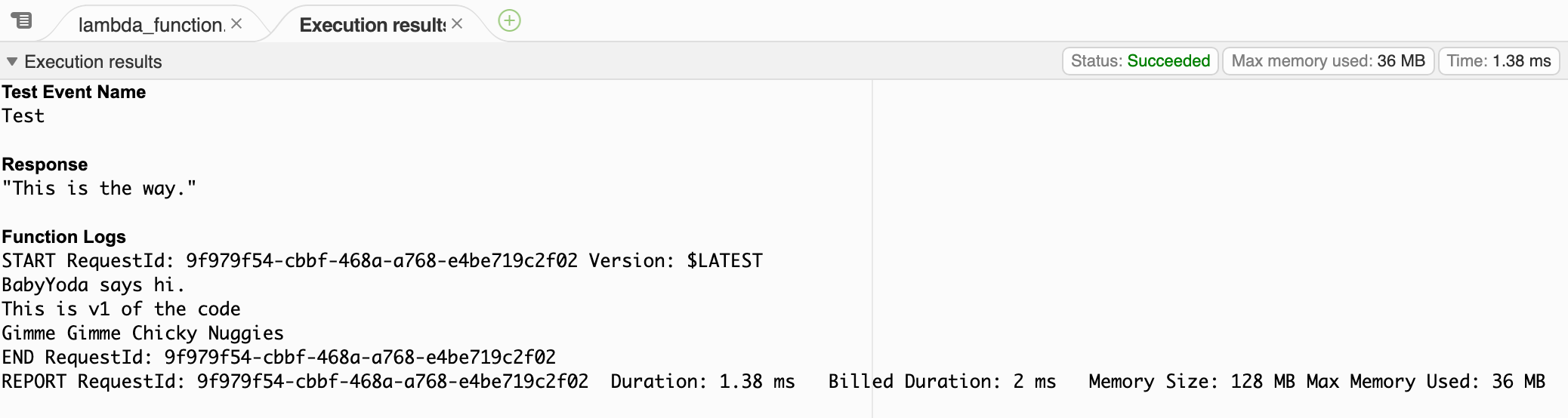
- Notice that this is the $latest and every time you change this and deploy and test, it remains the $latest.
Version 1
- Click on the Versions tab and then
Publish a new version. - Name this v1 and click Save
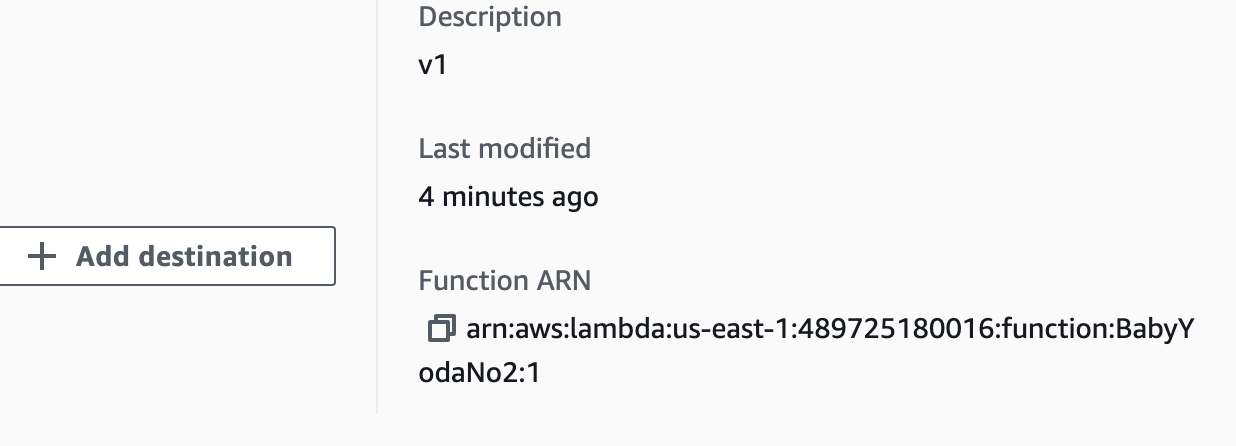
- Click back on the functions and notice that the ARN for the default is an unqualified ARN (which means that it points to the latest and doesn't have a :v1 after it)
- Click back on the versions tab and then click v1 and you'll notice that this has a qualified ARN.
- Click on the Code tab and you'll get this message as you cannot edit versions of the code. Remember that versions are immutable.
Version 2
- Click edit code and it takes you back to the unqualified version of the code.
- Update the code as follows:
import json
def lambda_handler(event, context):
print ('BabyYoda uses the force to move the chicky nuggies.')
print ('This is v2 of the code')
print ('Gimme Gimme Chicky Nuggies')
return "This is the way."
- Deploy this code.
- $latest is now v2 of the code and there's still a v1 out there.
- Click on the Versions tab and then publish a new version.
- Call this v2 and save.
- Look at the code for v2 and then look at the code for v1. Notice that the code is exactly how you'd imagine. Immutable and versioned.
Aliases
- Click on the Aliases tab.
- Click create new alias and name it Production and then select v1.
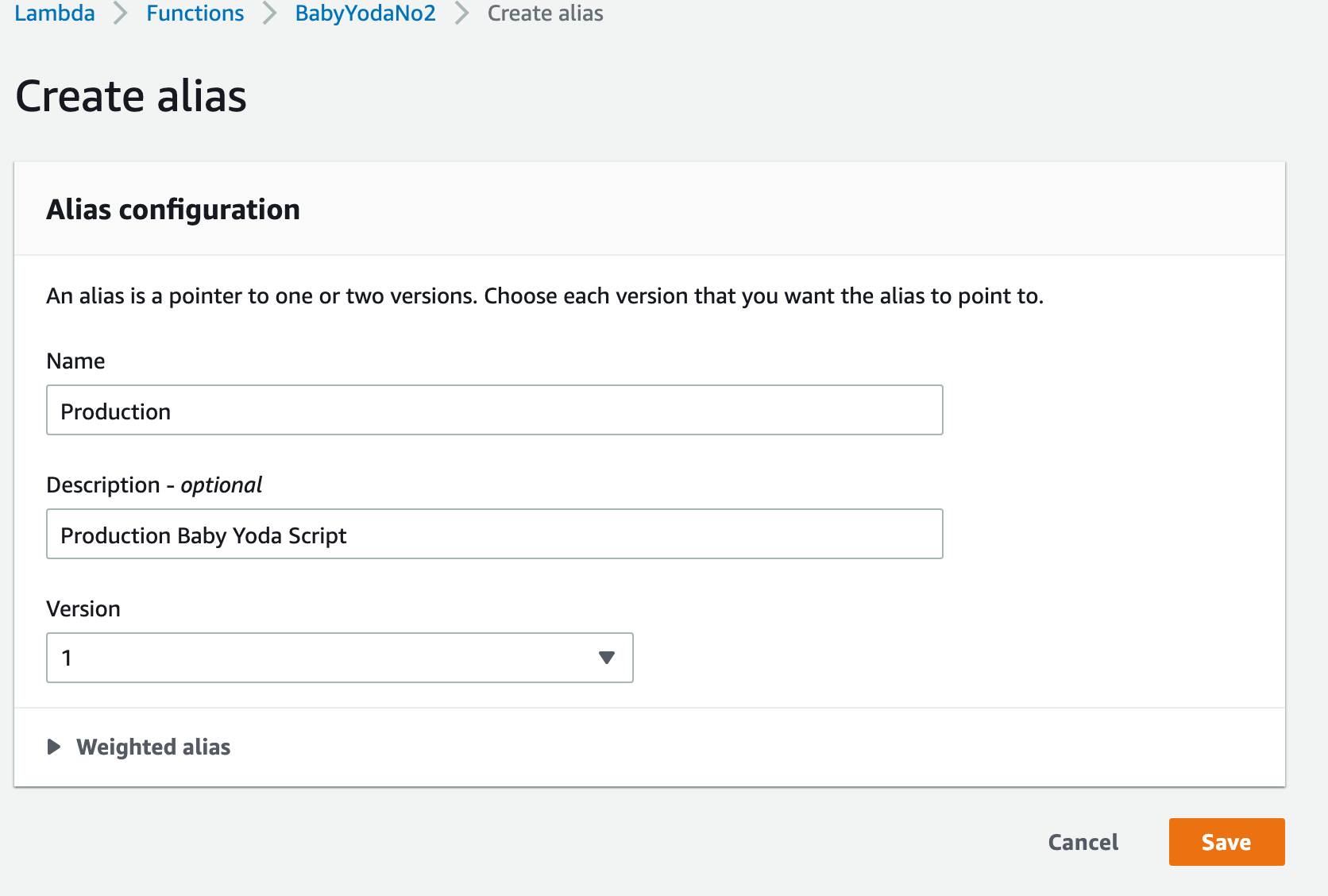
- You can test this alias if you want.
- Create a new alias and name it Development and then select v2.
- What we've done here is simulate a working code release and a development code release.
Cutover v2 into Production.
- Click on the Aliases tab and then click on the Production alias. Click Edit.
- On the Weighted Alias section, select the additional version and set it to 50%. You can start this at 5, move to 10, move to 20, etc as confidence is gained, but for this, we'll give it a 50/50 shot of hitting either version.
- Test the Production version and notice you'll hit both versions almost like flipping a coin. You can legit use this code block as a coin flipping app. :)
Cleanup
Delete the function.
Lambda Environment Variables
Key Value Pairs.
- Associated with $latest or can be associated with a version (immutable)
- Can be accessed within the execution environment.
- Can be encrypted with KMS
- allows code execution to be adjusted based on variables.
Quick Demo
- Log into the Lambda console in your management account.
- Create a new function and name how you want to.
- Click on the configuration tab and then click on Environment Variables.
- Click Edit and then add your first variable and enter your Key Value pair.
- Name this ENV with the value of Production
- Change your code to this:
import json
import os
def lambda_handler(event, context):
print ('BabyYoda says the variable is loading...')
print (os.environ['ENV'])
print ('Gimme Gimme Chicky Nuggies')
return "This is the way."'
- Deploy and test.
- For practice, go try to rewrite this using any of the other runtimes.
Demo VPC Lambda and EFS
Demo.
Lambda Layers
Layers work by separating out the code from the libraries in the functions. This allows you to create multiple functions which reuse the same libraries without consuming as much space and resources.
- Deployment zips are smaller and the libraries are externalized and stored separately.
Quick Demo
- Log into management account and the N. Virginia region.
- Navigate to the Lambda console and create a new function using Python 3.8.
- Paste in the following code, deploy and test.
import numpy as np
from scipy.spatial import ConvexHull
def lambda_handler(event, context):
print("\nUsing NumPy\n")
print("random matrix_a =")
matrix_a = np.random.randint(10, size=(4, 4))
print(matrix_a)
print("random matrix_b =")
matrix_b = np.random.randint(10, size=(4, 4))
print(matrix_b)
print("matrix_a * matrix_b = ")
print(matrix_a.dot(matrix_b))
print("\nUsing SciPy\n")
num_points = 10
print(num_points, "random points:")
points = np.random.rand(num_points, 2)
for i, point in enumerate(points):
print(i, '->', point)
hull = ConvexHull(points)
print("The smallest convex set containing all",
num_points, "points has", len(hull.simplices),
"sides,\nconnecting points:")
for simplex in hull.simplices:
print(simplex[0], '<->', simplex[1])
- This should error out as there is no module loaded named
numpy - Navigate back to the code and scroll down and click Add a Layer.
- Choose AWS layers and select the Python SciPy layer.
- Select a version and then add it. Test and run it and you'll notice that the function now runs.
Lambda Container Images
Lambda is a function as a service product. You write a function, you upload a function, Lambda executes the function
Problem is that organizations use containers and CI/CD processes built for containers
How this works is that CI/CD system accepts commits from the repo and builds the images. These images include some emulation which includes:
- base layer
- dependencies
- emulation (RIE)
- code
The AWS image includes the same layers but not the emulation layer that can be added to the Elastic Container Registry.
Lambda and Application Load Balancers
Client talks to the ALB and the ALB synchronously invokes Lambda. Lambda runs the function which converts the JSON response to HTTP for the client.
This also uses multivalue headers that can query multiple key values sent by the client.
Demo - Pet Cuddle-o-tron
Demo
Simple Queue Service (SQS)
Public, Fully managed, Highly available queues
- Standard
- FIFO -256kb in size, any larger, store in S3 and link.
Received messages are hidden (VisibilityTimeout) Dead letter queues can be used for problem messages - can add some logic to process these as well. ASGs can scale and Lambdas can run based on the queue.
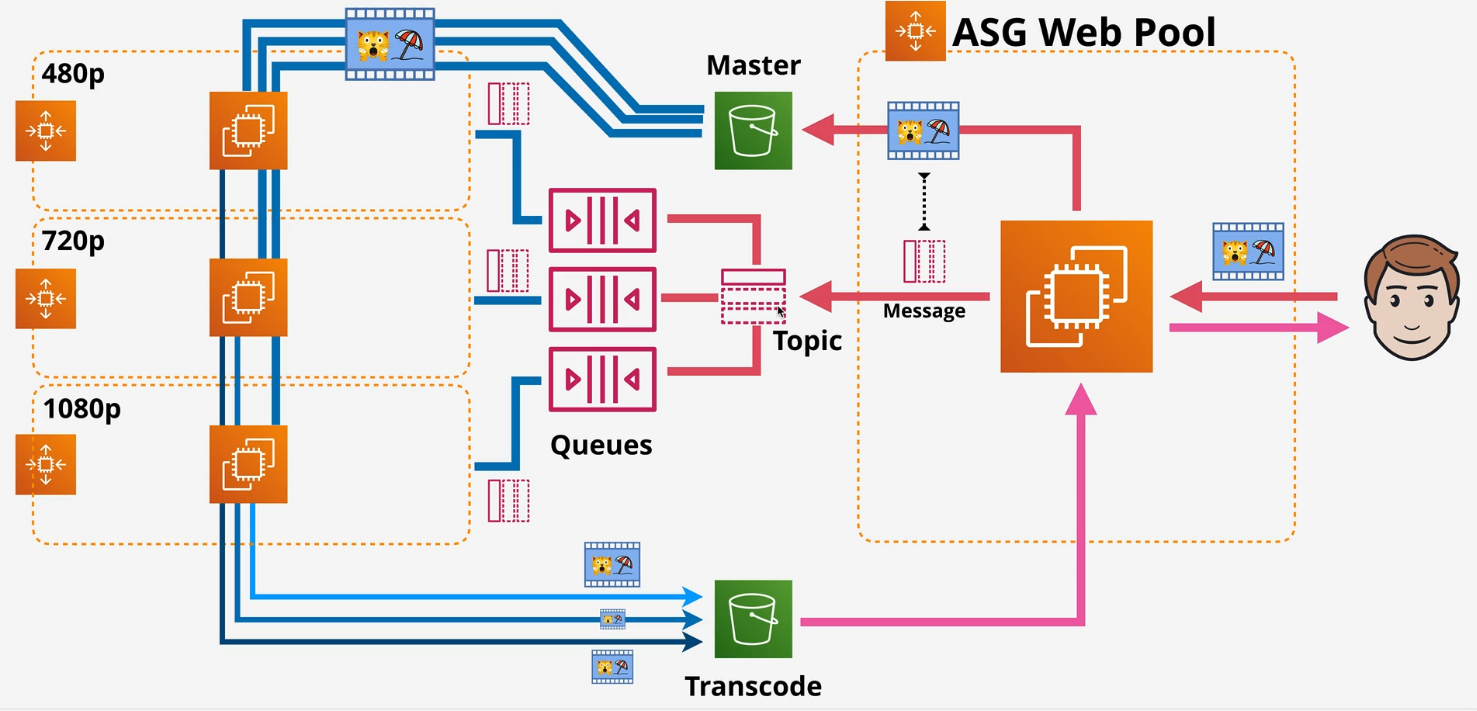
Standard queues - at least once FIFO queues - exactly once, in order. Billing is based on requests - requests are polling the SQS queue Short poll (immediate) costs more than Long polls - Long polls uses a waitTimeSeconds to wait for messages to build up before polling Encryption at rest using KMS and in transit.
Kinesis Data Streams
- Kinesis is a scalable streaming service
- Producers send data into a kinesis stream
- Consumers access from that stream.
- Streams can scale from low to near infinite data rates
- Public service and HA by design
- Streams store data in a 24 hour moving window. This window can be increased for additional cost.
- Kinesis streams contain 1+ shards.
- Kinesis data records are 1mb
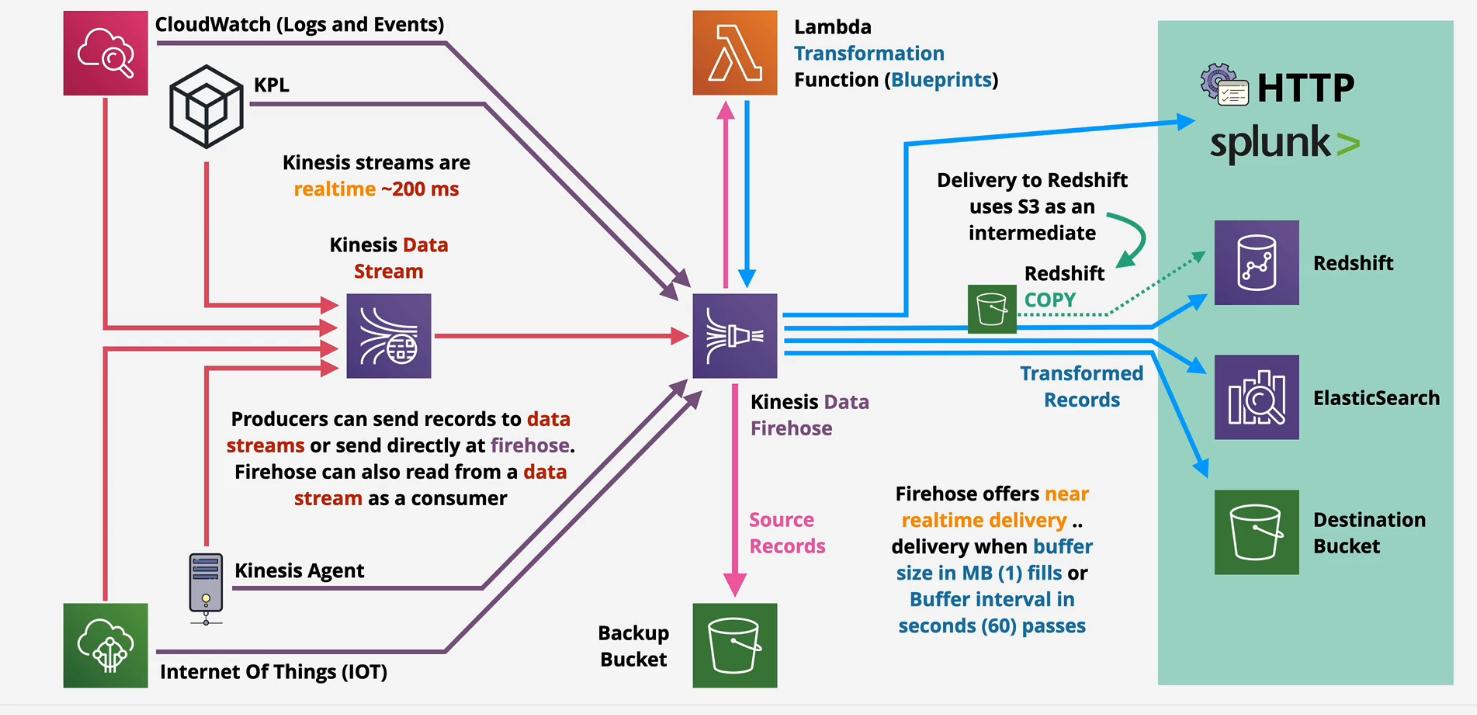
Kinesis Data Firehose
Takes the data from the stream and sprays like a firehose into something, like S3. Kinesis streams are real time, Kinesis Firehose is near real time.
When to use SQS or Kinesis
If this is about ingestion of data, choose Kinesis.
SQS is used for decoupling and asynchronous communications
Kinesis Data Firehose - In depth
Kinesis only has a 24 hour window, but if we wanted to load that data after that window into a data lake or a data store, we'd use Kinesis Firehose.
- Near Real Time, not real time
- supports transformation of data on the fly with Lambda
- billing is based on volume through the Firehose.
- Redshift uses a S3 bucket as an intermediate.
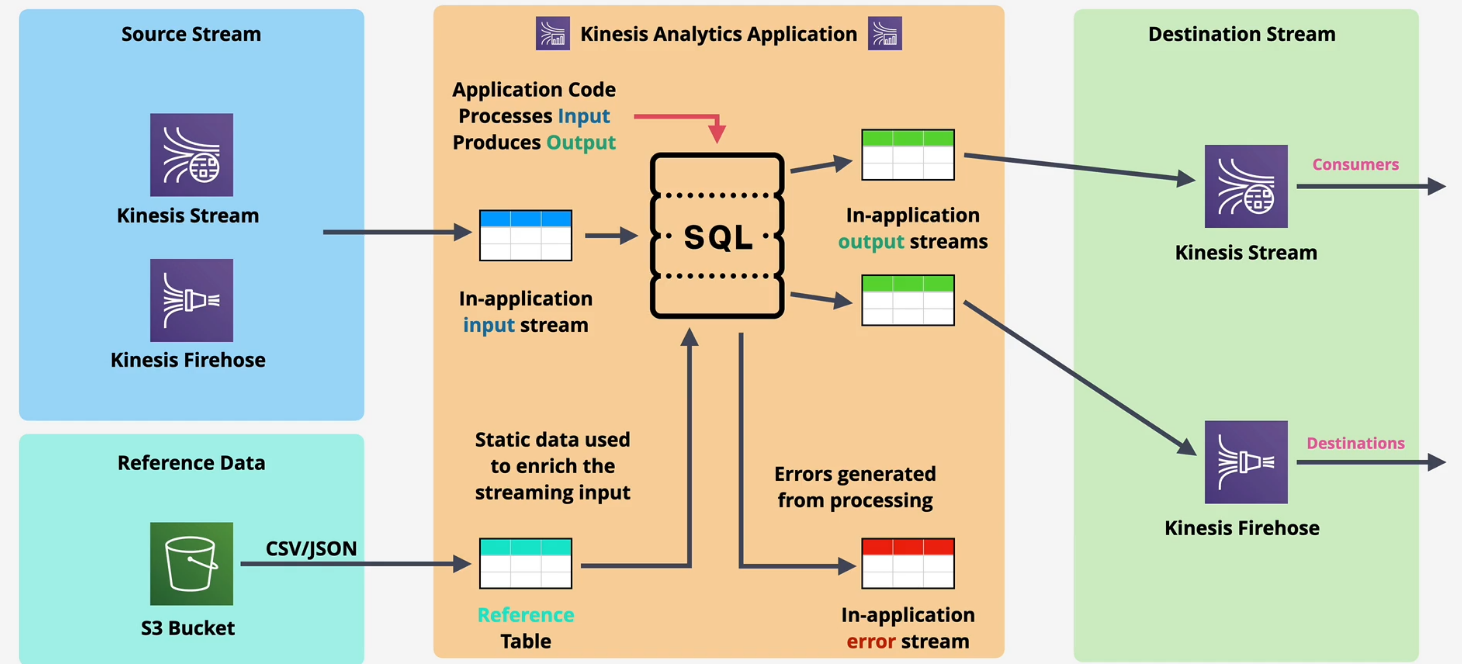
Kinesis Data Analytics
- Real Time processing of data using SQL
- Ingests from Kinesis Data Streams or Kinesis Firehose
- Destinations:
- Firehose (S3, Redshift, ElasticSearch and Splunk)
- AWS Lambda
- Kinesis Data Streams
When to use Kinesis Data Analytics
- Streaming data needing real-time SQL processing
- Time series analytics - elections/e-sports
- Real time dashboards - leaderboards for games
- Real time metrics - security and response teams
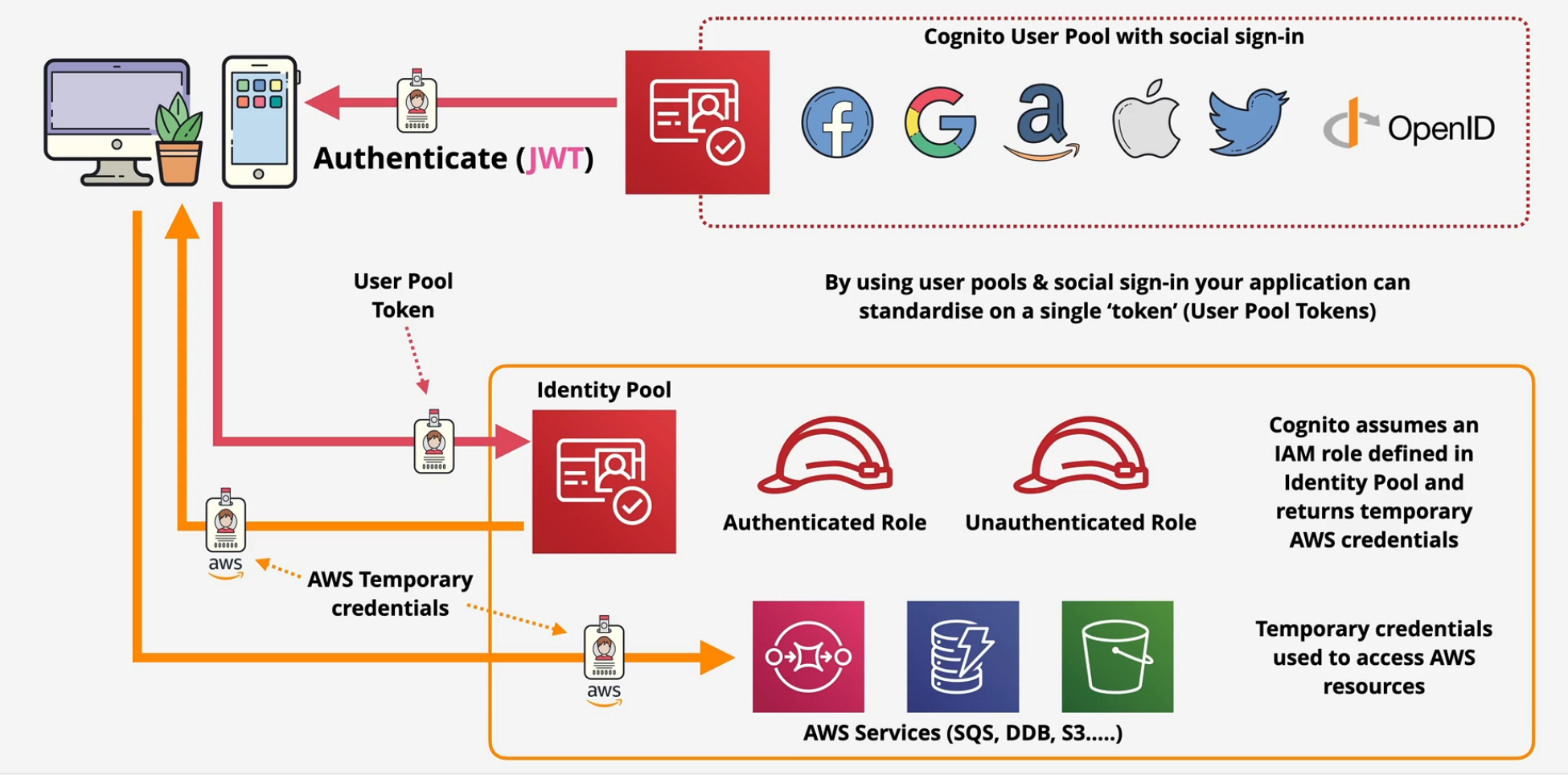
Amazon Cognito
Provides Authentication, Authorization and user management for web/mobile apps.
- User Pool - Sign in and get a JSON Web Token (JWT) - most services don't use JWT's, they use actual AWS credentials.
- Identity Pool - allows you to offer access to Temporary AWS credentials
- unauthenticated Identities - guest users
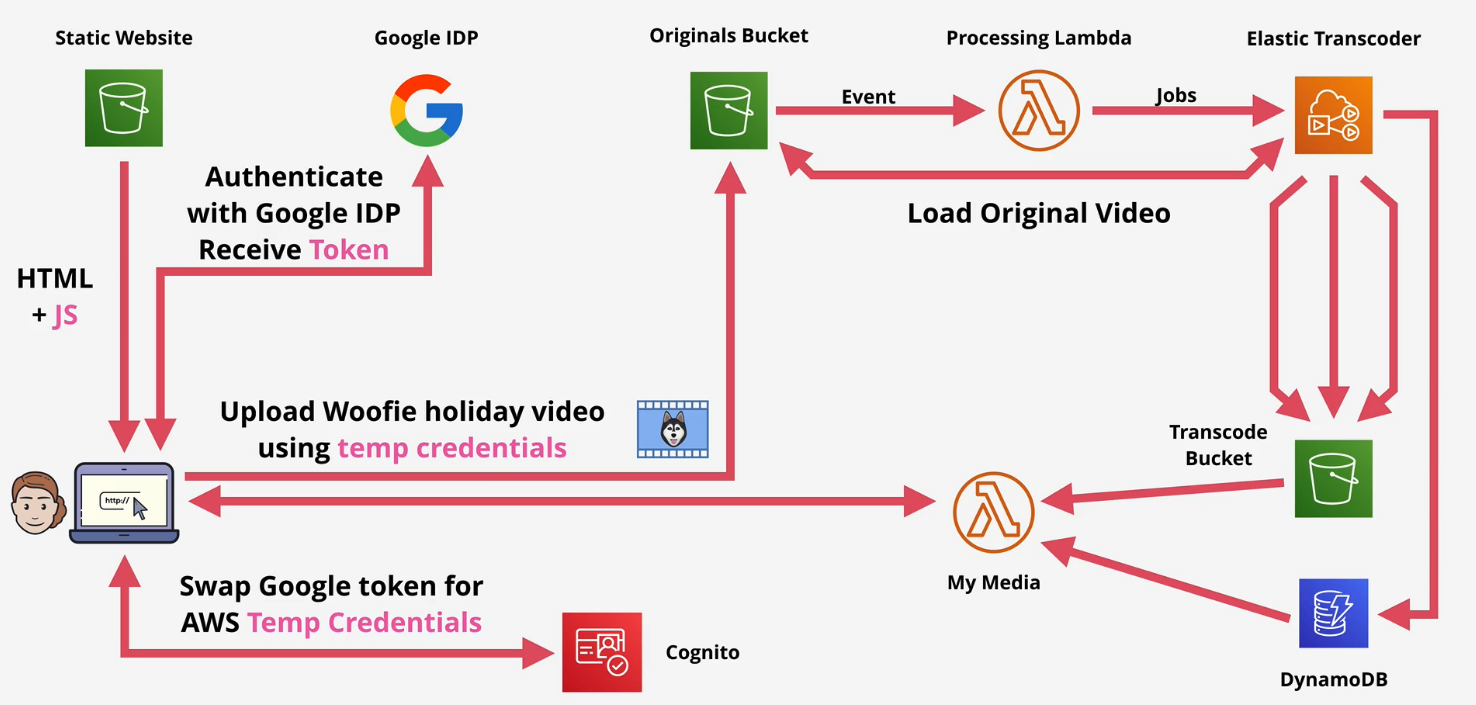
- Federated identities - Swaps Google, Facebook, Twitter, SAML 2.0 and User Pool for short term AWS credentials to access AWS resources.
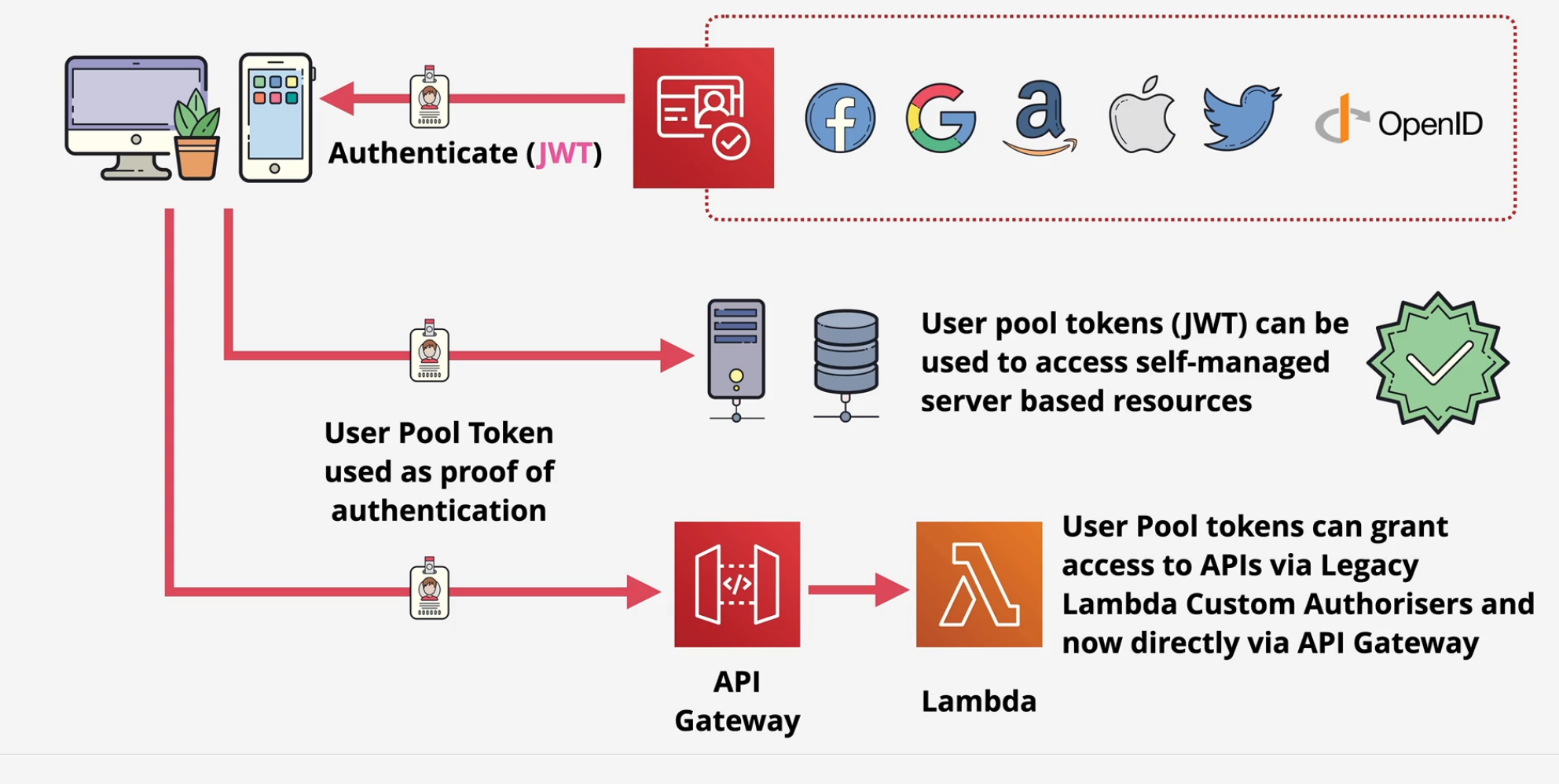
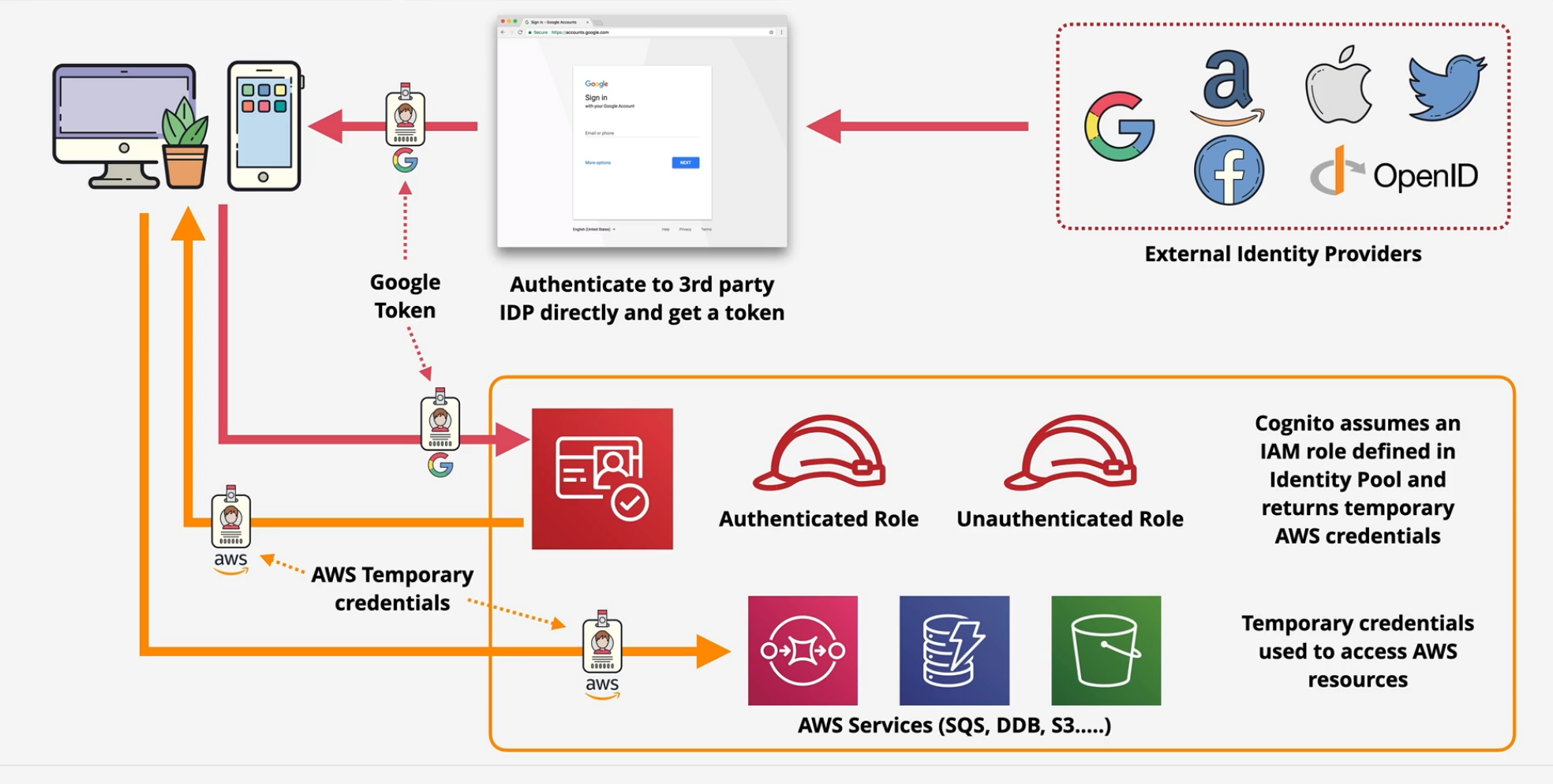
Key Tip: Use the user pools to generate the JWT from the External Identity providers and then use the identity pools to swap those JWTs for temporary AWS credentials.
Web Identity Federation
Allow for a near infinite amount of users if they authenticate via External Identity Providers